*파이썬, 주피터노트북 설치가 안되어있다면 아래 url참고
웹 크롤링 연습으로 프리미어리그 팀 순위 정보를 조회해보도록 하겠습니다.
대표적인 BeautifulSoup을 사용해 진행하도록 하겠습니다.
BeautifulSoup 사용
해외축구 메인 화면 url : https://sports.news.naver.com/wfootball/index.nhn
해외축구 : 네이버 스포츠
스포츠의 시작과 끝!
sports.news.naver.com
프리미어리그 기간동안 네이버 해외축구 메인화면에는 항상 프리미어리그 팀 순위 정보가 있습니다.
해당 영역을 개발자도구로 html태그를 확인해서 접근 해주기만 하면 됩니다.
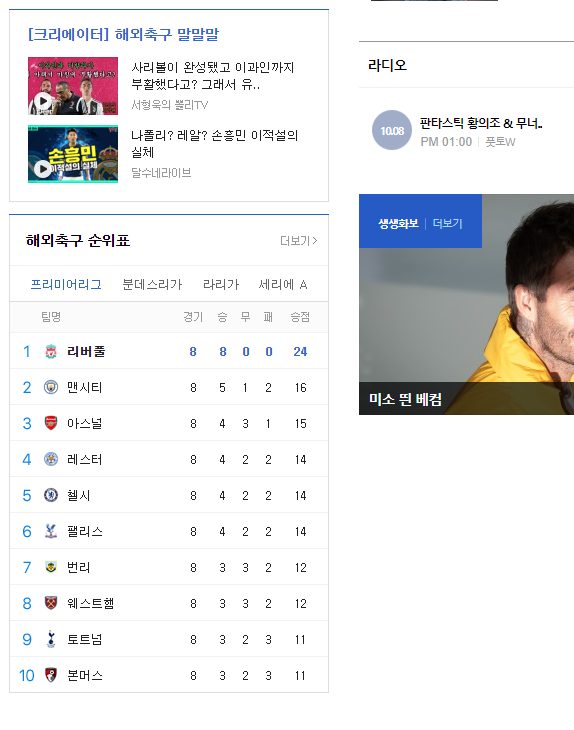
개발자도구로 확인해보니,
아래 _team_rank_epl id 값으로 해당 div 영역을 접근 할 수 있겠네요.
그럼 코드로 구현해보도록 하겠습니다.

아래 코드를 확인해보시면 _team_rank_epl id값으로 해당 div태그 정보를 조회해온 것을 알 수 있습니다.
그럼 원하는 정보만 짤라보도록 하겠습니다.

tr태그를 활용해 1위 정보만 가져와 보았습니다.
순위정보와 팀명 정보가 있는 span태그에 접근하면 될 것으로 보이네요

최종적으로 1~10위까지의 순위,팀명을 가져온 결과 입니다.
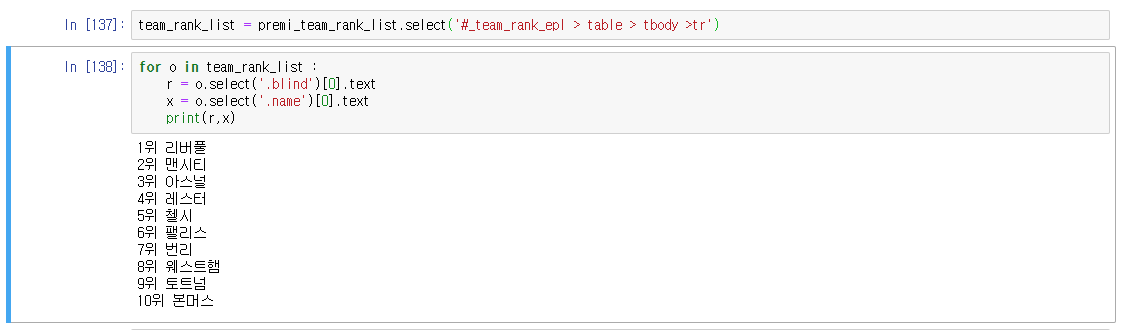
[복사코드]
|
import requests
from bs4 import BeautifulSoup
naver_wfootball = "https://sports.news.naver.com/wfootball/index.nhn"
premi_team_rank = requests.get(naver_wfootball)
#team_rank_list = premi_team_rank_list.select('#_team_rank_epl > table > tbody >tr')[0]
#team_rank_list
for o in team_rank_list :
r = o.select('.blind')[0].text
x = o.select('.name')[0].text
print(r,x)
http://colorscripter.com/info#e" target="_blank" style="color:#e5e5e5text-decoration:none">Colored by Color Scripter
|
*심화
그럼 전체 20팀의 순위와 추가적인 상세정보를 가져와 보도록 해보겠습니다.
전체 순위정보는 아래 url에서 확인 가능합니다.
https://sports.news.naver.com/wfootball/record/index.nhn?category=epl&tab=team
네이버 스포츠
스포츠의 시작과 끝!
sports.news.naver.com
위의 1~10위 팀 정보가져오기 예제와
동일한 방식으로 개발자도구를 활용해 태그 정보를 확인해서 확인하면 될 것 같지만
쉽지 않습니다. html페이지가 브라우저에 노출된 후 자바스크립트로 값이 이후에 제어되어
원하는 데이터를 조회하기가 어렵습니다.
이러한 상황에서 결과 조회를 위해선 Selenium이라는 라이브러리 사용이 필요합니다.
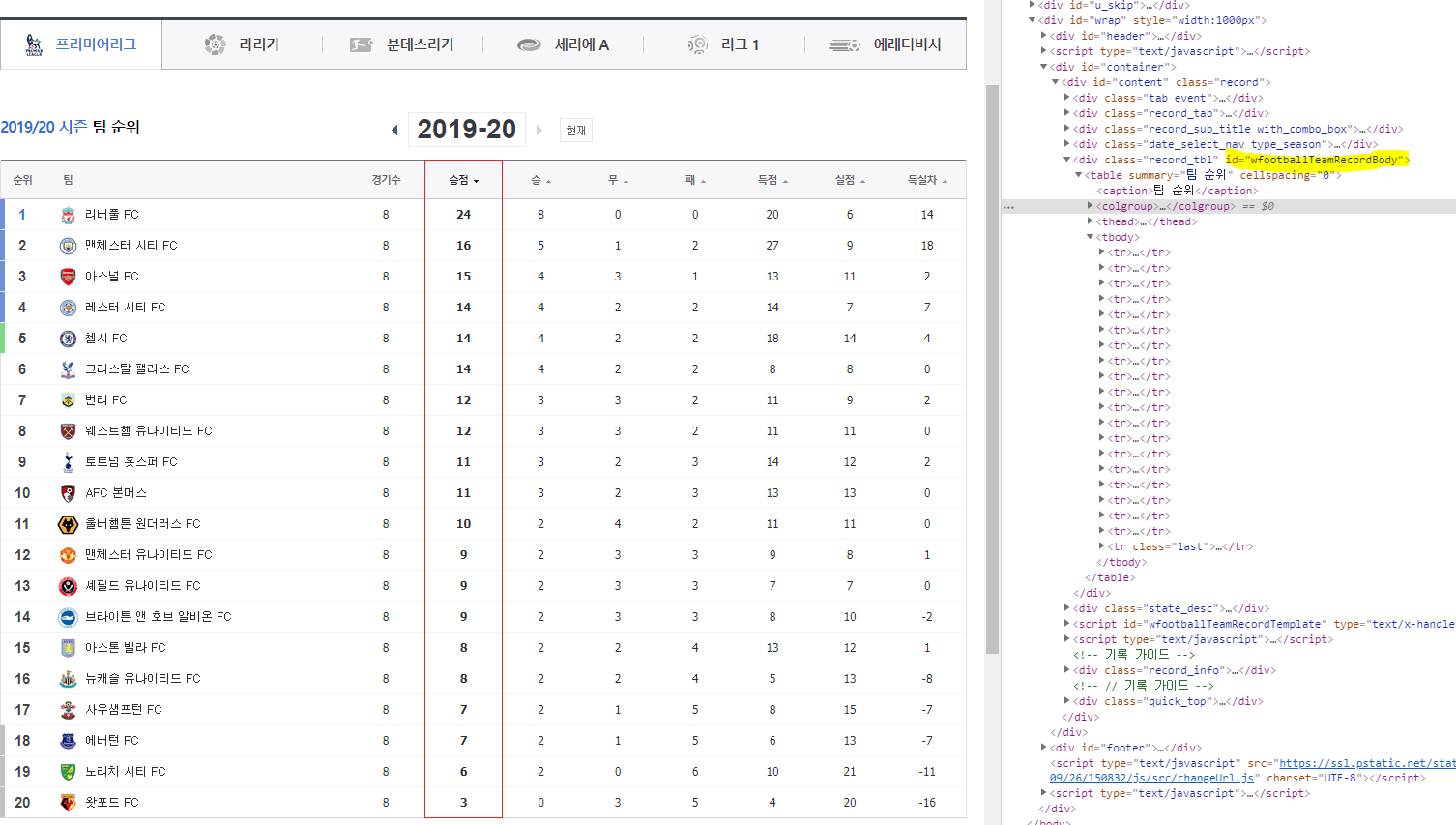
1부리그 전체팀의 정보 조회하기 (Selenium + BeautifulSoup사용) 예제는 아래 포스팅을 참고해주세요
[python] 파이썬 웹 크롤링 - 4 : 프리미어리그 전체 팀 순위 조회(Selenium, BeautifulSoup)
*파이썬, 주피터노트북 설치가 안되어있다면 아래 url참고 https://vmpo.tistory.com/entry/python-%EC%95%84%EB%82%98%EC%BD%98%EB%8B%A4anaconda-%EC%84%A4%EC%B9%98%ED%95%98%EA%B8%B0-%EC%9C%88%EB%8F%84%EC%9..
vmpo.tistory.com
'python > 크롤링' 카테고리의 다른 글
| [python] 파이썬 웹 크롤링 - 6 : 한국 피파랭킹 크롤링 (0) | 2019.11.12 |
|---|---|
| [python] 파이썬 웹 크롤링 - 5 : 네이트 판 톡커들의 선택 랭킹 (2) | 2019.11.12 |
| [python] 파이썬 웹 크롤링 - 4 : 프리미어리그 전체 팀 순위 조회(Selenium, BeautifulSoup) (0) | 2019.10.10 |
| [python] 파이썬 웹 크롤링 - 2 : 네이버 실시간 검색어 (0) | 2019.10.10 |
| [python] 파이썬 웹 크롤링 -1 : 네이버 스포츠 댓글많은 뉴스(jupyter notebook, BeautifulSoup) (0) | 2019.10.09 |








최근댓글